tascCODA - Tree-aggregated compositional analysis#
This notebook is a tutorial on how to use tascCODA Ostner et al., 2021 for tree-aggregated compositional analysis of high-throughput sequencing (HTS) data.
For this example, we use single-cell RNA sequencing data [OCM21]. However, there are no limitations to use tascCODA with other HTS data, such as 16S rRNA sequencing.
The particular dataset for this analysis was generated by Smillie et al., 2019. It contains samples from two different regions in the small intestine of mice - Epithelium and Lamina Propria - and three different inflammation conditions - healthy, non-inflamed and inflamed. In total, we have 365.492 cells from 51 cell types in 133 samples.
import matplotlib.pyplot as plt
import pertpy as pt
Dataset#
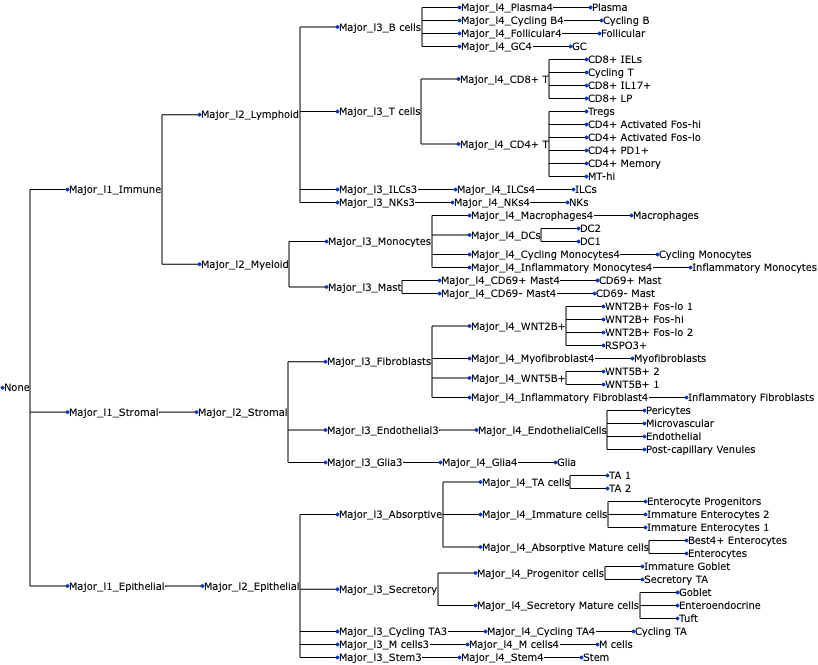
First, we read in the per-cell data. In this dataset, samples are specified as “Subject”, and cell types are denoted as “Cluster”. Interesting covariates are the samples’ location and health status. The columns “Major_l1” - “Major_l4” and “Cluster” describe a lineage tree over the cell types.
smillie_counts = pt.dt.smillie_2019()
smillie_counts.obs
| Origin | Subject | Sample | Location | Replicate | Health | Cluster | nGene | nUMI | Major_l1 | Major_l2 | Major_l3 | Major_l4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N7.EpiA.AAGGCTACCCTTTA | Imm | N7 | EpiA | Epi | A | Non-inflamed | Plasma | 624.0 | 7433.0 | Immune | Lymphoid | B cells | Plasma4 |
| N7.EpiA.AAGGTGCTACGGAG | Imm | N7 | EpiA | Epi | A | Non-inflamed | CD8+ IELs | 558.0 | 1904.0 | Immune | Lymphoid | T cells | CD8+ T |
| N7.EpiA.AAGTAACTTGCTTT | Imm | N7 | EpiA | Epi | A | Non-inflamed | CD8+ IELs | 437.0 | 1366.0 | Immune | Lymphoid | T cells | CD8+ T |
| N7.EpiA.ACAATAACCCTCAC | Imm | N7 | EpiA | Epi | A | Non-inflamed | Plasma | 484.0 | 5161.0 | Immune | Lymphoid | B cells | Plasma4 |
| N7.EpiA.ACAGTTCTTCTACT | Imm | N7 | EpiA | Epi | A | Non-inflamed | CD8+ IELs | 470.0 | 1408.0 | Immune | Lymphoid | T cells | CD8+ T |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| N110.LPB.TTTGGTTGTGTGGCTC | Epi | N110 | LPB | LP | B | Inflamed | Immature Enterocytes 2 | 2553.0 | 11705.0 | Epithelial | Epithelial | Absorptive | Immature cells |
| N110.LPB.TTTGGTTTCCTTAATC | Epi | N110 | LPB | LP | B | Inflamed | TA 2 | 3234.0 | 16164.0 | Epithelial | Epithelial | Absorptive | TA cells |
| N110.LPB.TTTGGTTTCTTACCTA | Epi | N110 | LPB | LP | B | Inflamed | Enterocyte Progenitors | 258.0 | 384.0 | Epithelial | Epithelial | Absorptive | Immature cells |
| N110.LPB.TTTGTCAAGGATGGAA | Epi | N110 | LPB | LP | B | Inflamed | TA 1 | 487.0 | 772.0 | Epithelial | Epithelial | Absorptive | TA cells |
| N110.LPB.TTTGTCAGTTGTTTGG | Epi | N110 | LPB | LP | B | Inflamed | TA 1 | 363.0 | 747.0 | Epithelial | Epithelial | Absorptive | TA cells |
365492 rows × 13 columns
smillie_counts
AnnData object with n_obs × n_vars = 365492 × 18172
obs: 'Origin', 'Subject', 'Sample', 'Location', 'Replicate', 'Health', 'Cluster', 'nGene', 'nUMI', 'Major_l1', 'Major_l2', 'Major_l3', 'Major_l4'
Next, we convert the data to a (samples x cell types) object.
To identify the statistical samples, we need to combine the “Subject” and “Sample” columns.
We also need to extract the tree-structured cell lineage information (Lineages Major_l1 - Major_l4) from the data, generate a Newick string through tasccoda.tree_utils.df2newick() and convert it into a ete3 tree object. This is all done within the load function by specifying.
tasccoda_model = pt.tl.Tasccoda()
smillie_data = tasccoda_model.load(
smillie_counts,
type="cell_level",
cell_type_identifier="Cluster",
sample_identifier=["Subject", "Sample"],
covariate_obs=["Location", "Health"],
levels_orig=["Major_l1", "Major_l2", "Major_l3", "Major_l4", "Cluster"],
add_level_name=True,
)
smillie_data
MuData object with n_obs × n_vars = 365625 × 18223
2 modalities
rna: 365492 × 18172
obs: 'Origin', 'Subject', 'Sample', 'Location', 'Replicate', 'Health', 'Cluster', 'nGene', 'nUMI', 'Major_l1', 'Major_l2', 'Major_l3', 'Major_l4', 'scCODA_sample_id'
coda: 133 × 51
obs: 'Location', 'Health', 'Sample', 'Subject'
var: 'n_cells'
uns: 'tree'We can also visualize the tree:
tasccoda_model.plot_draw_tree(smillie_data["coda"])
For this tutorial, we focus on finding changes between healthy and non-inflamed tissue in the Lamina Propria. Therefore, we subset the data accordingly, and end up with 48 samples:
smillie_data.mod["coda_LP"] = smillie_data["coda"][
(smillie_data["coda"].obs["Health"].isin(["Healthy", "Non-inflamed"]))
& (smillie_data["coda"].obs["Location"] == "LP")
]
smillie_data
MuData object with n_obs × n_vars = 365625 × 18223
3 modalities
rna: 365492 × 18172
obs: 'Origin', 'Subject', 'Sample', 'Location', 'Replicate', 'Health', 'Cluster', 'nGene', 'nUMI', 'Major_l1', 'Major_l2', 'Major_l3', 'Major_l4', 'scCODA_sample_id'
coda: 133 × 51
obs: 'Location', 'Health', 'Sample', 'Subject'
var: 'n_cells'
uns: 'tree'
coda_LP: 48 × 51
obs: 'Location', 'Health', 'Sample', 'Subject'
var: 'n_cells'
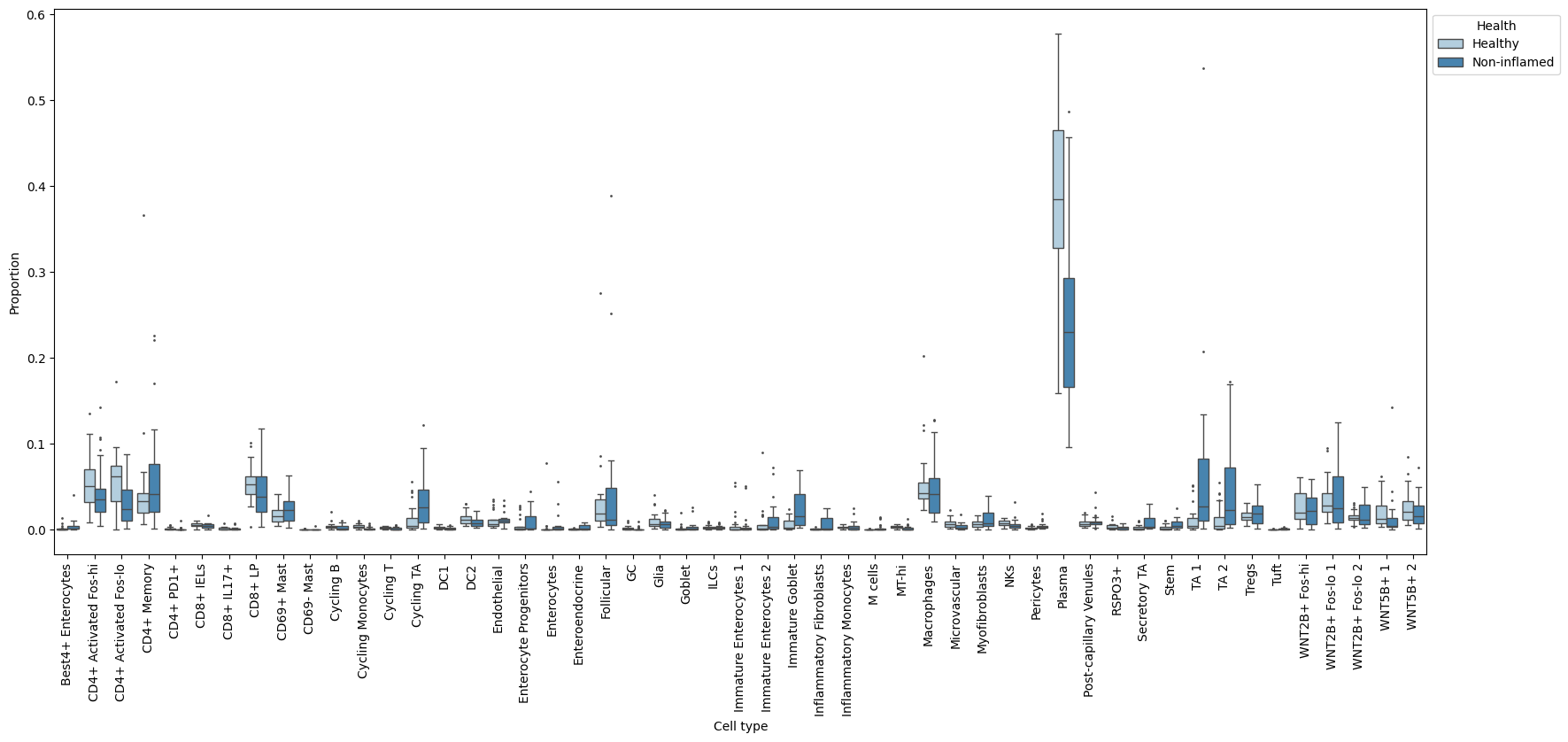
uns: 'tree'A quick plot of the data with the sccoda.util.data_visualization module shows us that there are some changes in relative abundance in the data:
tasccoda_model.plot_boxplots(smillie_data, modality_key="coda_LP", feature_name="Health", figsize=(20, 8))
plt.show()
Run tascCODA#
Inferring credible effects with tascCODA on our data is now simply a matter of running the sampling process. The model creation and inference works analogous to scCODA (see the scCODA quickstart tutorial)
As hyperparameters, we have to specify in the prepare function:
The reference cell type (which is assumed to be unchanged between the conditions): We use the
automaticsetting here, which chooses a reference that induces minimal compositional effects (here we use the automatic suggestion - NK cells)The model formula (R-style formula string, just as in scCODA)
The aggregation bias \(\phi\), defined in the tascCODA paper. We go with an unbiased aggregation (
pen_args={"phi": 0}) here.The key in
.unsof our MuData modality where the tree is saved.
Then, we run No-U-turn sampling via run_nuts with the default settings of 11.000 samples, of which 1.000 are discarded as burn-in
smillie_data = tasccoda_model.prepare(
smillie_data,
modality_key="coda_LP",
tree_key="tree",
reference_cell_type="automatic",
formula="Health",
pen_args={"phi": 0},
)
smillie_data
• Automatic reference selection! Reference cell type set to NKs
• Zero counts encountered in data! Added a pseudocount of 0.5.
/Users/luisheinzlmeier/Library/Application Support/hatch/env/virtual/pertpy/RYWIBvOS/hatch-test.py3.14-stable/lib/python3.14/site-packages/anndata/_core/anndata.py:639: FutureWarning: Setting element `.X` of view of `AnnData` object will obey copy-on-write semantics in the next minor release.
if self._handle_view_X_cow(value):
/Users/luisheinzlmeier/Desktop/Repos/pertpy/pertpy/tools/_coda/_base_coda.py:186: FutureWarning: You are attempting to set `X` to a matrix on a view which has non-unique indices. The resulting `adata.X` will likely not equal the value to which you set it. To avoid this potential issue, please make a copy of the data first. In the future, this operation will throw an error.
sample_adata.X = sample_adata.X.astype(dtype)
/Users/luisheinzlmeier/Desktop/Repos/pertpy/pertpy/tools/_coda/_base_coda.py:186: ImplicitModificationWarning: Modifying `X` on a view results in data being overridden
sample_adata.X = sample_adata.X.astype(dtype)
/Users/luisheinzlmeier/Desktop/Repos/pertpy/pertpy/tools/_coda/_base_coda.py:193: ImplicitModificationWarning: Setting element `.obsm['covariate_matrix']` of view, initializing view as actual.
sample_adata.obsm["covariate_matrix"] = np.array(covariate_matrix[:, 1:]).astype(dtype)
MuData object with n_obs × n_vars = 365625 × 18223
3 modalities
rna: 365492 × 18172
obs: 'Origin', 'Subject', 'Sample', 'Location', 'Replicate', 'Health', 'Cluster', 'nGene', 'nUMI', 'Major_l1', 'Major_l2', 'Major_l3', 'Major_l4', 'scCODA_sample_id'
coda: 133 × 51
obs: 'Location', 'Health', 'Sample', 'Subject'
var: 'n_cells'
uns: 'tree'
coda_LP: 48 × 51
obs: 'Location', 'Health', 'Sample', 'Subject'
var: 'n_cells'
uns: 'tree', 'scCODA_params'
obsm: 'covariate_matrix', 'sample_counts'tasccoda_model.run_nuts(smillie_data, modality_key="coda_LP")
[2026-06-16 12:08:29,801] Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: dlopen(libtpu.so, 0x0001): tried: 'libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OSlibtpu.so' (no such file), '/opt/homebrew/lib/libtpu.so' (no such file), '/System/Volumes/Preboot/Cryptexes/OS/opt/homebrew/lib/libtpu.so' (no such file), '/usr/lib/libtpu.so' (no such file, not in dyld cache), 'libtpu.so' (no such file)
sample: 100%|██████████| 11000/11000 [03:09<00:00, 57.92it/s, 63 steps of size 8.77e-02. acc. prob=0.92]
[2026-06-16 12:11:45,155] Found 'auto' as default backend, checking available backends
[2026-06-16 12:11:45,155] Matplotlib is available, defining as default backend
[2026-06-16 12:11:45,248] arviz_base 1.1.0 available, exposing its functions as part of the `arviz` namespace
[2026-06-16 12:11:45,509] arviz_stats 1.1.0 available, exposing its functions as part of the `arviz` namespace
[2026-06-16 12:11:45,851] arviz_plots 1.1.0 available, exposing its functions as part of the `arviz` namespace
Result analysis#
Calling summary, we can see the most relevant information for further analysis:
tasccoda_model.summary(smillie_data, modality_key="coda_LP")
Compositional Analysis summary ┌────────────────────────────────────────────┬────────────────────────────────────────────────────────────────────┐ │ Name │ Value │ ├────────────────────────────────────────────┼────────────────────────────────────────────────────────────────────┤ │ Data │ Data: 48 samples, 51 cell types │ │ Reference cell type │ NKs │ │ Formula │ Health │ └────────────────────────────────────────────┴────────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐ │ Intercepts │ ├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ Final Parameter Expected Sample │ │ Cluster │ │ Best4+ Enterocytes -1.2 10.699 │ │ CD4+ Activated Fos-hi 1.5 159.196 │ │ CD4+ Activated Fos-lo 1.5 159.196 │ │ CD4+ Memory 1.3 130.339 │ │ CD4+ PD1+ -0.95 13.738 │ │ CD8+ IELs -0.13 31.191 │ │ CD8+ IL17+ -0.82 15.645 │ │ CD8+ LP 1.6 175.939 │ │ CD69+ Mast 0.56 62.186 │ │ CD69- Mast -1.4 8.759 │ │ Cycling B -0.49 21.761 │ │ Cycling Monocytes -0.62 19.109 │ │ Cycling T -0.72 17.290 │ │ Cycling TA 0.077 38.365 │ │ DC1 -0.64 18.730 │ │ DC2 0.3 47.949 │ │ Endothelial 0.11 39.652 │ │ Enterocyte Progenitors -0.93 14.015 │ │ Enterocytes -1.2 10.699 │ │ Enteroendocrine -1.3 9.681 │ │ Follicular 0.81 79.849 │ │ GC -0.91 14.298 │ │ Glia -0.14 30.881 │ │ Goblet -1.2 10.699 │ │ ILCs -0.87 14.882 │ │ Immature Enterocytes 1 -1.1 11.824 │ │ Immature Enterocytes 2 -0.85 15.182 │ │ Immature Goblet -0.29 26.579 │ │ Inflammatory Fibroblasts -0.95 13.738 │ │ Inflammatory Monocytes -0.57 20.088 │ │ M cells -1.4 8.759 │ │ MT-hi -0.73 17.118 │ │ Macrophages 1.5 159.196 │ │ Microvascular -0.33 25.537 │ │ Myofibroblasts -0.022 34.748 │ │ NKs -0.4 23.811 │ │ Pericytes -0.67 18.177 │ │ Plasma 3.5 1176.307 │ │ Post-capillary Venules -0.0011 35.482 │ │ RSPO3+ -0.66 18.359 │ │ Secretory TA -0.89 14.587 │ │ Stem -0.82 15.645 │ │ TA 1 0.043 37.082 │ │ TA 2 -0.13 31.191 │ │ Tregs 0.67 69.417 │ │ Tuft -1.5 7.926 │ │ WNT2B+ Fos-hi 0.68 70.115 │ │ WNT2B+ Fos-lo 1 1.1 106.712 │ │ WNT2B+ Fos-lo 2 0.51 59.153 │ │ WNT5B+ 1 0.3 47.949 │ │ WNT5B+ 2 0.72 72.976 │ └─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐ │ Effects │ ├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ Effect Expected Sample log2-fold change │ │ Covariate Cell Type │ │ Health[T.Non-inflamed] Best4+ Enterocytes 0.116 20.861 0.963 │ │ CD4+ Activated Fos-hi -0.643 145.291 -0.132 │ │ CD4+ Activated Fos-lo -0.766 128.441 -0.310 │ │ CD4+ Memory -0.643 118.954 -0.132 │ │ CD4+ PD1+ -0.643 12.538 -0.132 │ │ CD8+ IELs -0.643 28.467 -0.132 │ │ CD8+ IL17+ -0.643 14.278 -0.132 │ │ CD8+ LP -0.643 160.572 -0.132 │ │ CD69+ Mast -0.161 91.873 0.563 │ │ CD69- Mast -0.161 12.941 0.563 │ │ Cycling B -0.726 18.279 -0.252 │ │ Cycling Monocytes -0.506 19.998 0.066 │ │ Cycling T -0.643 15.780 -0.132 │ │ Cycling TA 0.116 74.804 0.963 │ │ DC1 -0.506 19.602 0.066 │ │ DC2 -0.506 50.180 0.066 │ │ Endothelial -0.337 49.121 0.309 │ │ Enterocyte Progenitors 0.116 27.327 0.963 │ │ Enterocytes 0.116 20.861 0.963 │ │ Enteroendocrine 0.116 18.876 0.963 │ │ Follicular -0.726 67.070 -0.252 │ │ GC -0.726 12.010 -0.252 │ │ Glia -0.337 38.256 0.309 │ │ Goblet 0.116 20.861 0.963 │ │ ILCs 0.000 25.833 0.796 │ │ Immature Enterocytes 1 0.116 23.055 0.963 │ │ Immature Enterocytes 2 0.116 29.603 0.963 │ │ Immature Goblet 0.116 51.825 0.963 │ │ Inflammatory Fibroblasts -0.337 17.018 0.309 │ │ Inflammatory Monocytes -0.506 21.023 0.066 │ │ M cells 0.116 17.079 0.963 │ │ MT-hi -0.643 15.623 -0.132 │ │ Macrophages -0.506 166.603 0.066 │ │ Microvascular -0.337 31.636 0.309 │ │ Myofibroblasts -0.337 43.047 0.309 │ │ NKs 0.000 41.332 0.796 │ │ Pericytes -0.337 22.517 0.309 │ │ Plasma -0.948 791.531 -0.572 │ │ Post-capillary Venules -0.337 43.956 0.309 │ │ RSPO3+ -0.337 22.744 0.309 │ │ Secretory TA 0.116 28.442 0.963 │ │ Stem 0.116 30.505 0.963 │ │ TA 1 0.305 87.363 1.236 │ │ TA 2 0.305 73.484 1.236 │ │ Tregs -0.643 63.354 -0.132 │ │ Tuft 0.116 15.454 0.963 │ │ WNT2B+ Fos-hi -0.337 86.859 0.309 │ │ WNT2B+ Fos-lo 1 -0.337 132.197 0.309 │ │ WNT2B+ Fos-lo 2 -0.337 73.280 0.309 │ │ WNT5B+ 1 -0.337 59.400 0.309 │ │ WNT5B+ 2 -0.337 90.404 0.309 │ └─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐ │ Nodes │ ├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ Covariate=Health[T.Non-inflamed]_node │ ├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ Final Parameter Is credible │ │ Node │ │ Major_l1_Immune 0.00 False │ │ Major_l2_Stromal -0.34 True │ │ Major_l2_Epithelial 0.12 True │ │ Major_l2_Lymphoid 0.00 False │ │ Major_l2_Myeloid -0.16 True │ │ Major_l3_Fibroblasts 0.00 False │ │ Major_l4_EndothelialCells 0.00 False │ │ Glia 0.00 False │ │ Major_l3_Absorptive 0.00 False │ │ Major_l3_Secretory 0.00 False │ │ Cycling TA 0.00 False │ │ M cells 0.00 False │ │ Stem 0.00 False │ │ Major_l3_B cells -0.73 True │ │ Major_l3_T cells -0.64 True │ │ ILCs 0.00 False │ │ NKs 0.00 False │ │ Major_l3_Monocytes -0.34 True │ │ Major_l3_Mast 0.00 False │ │ Major_l4_WNT2B+ 0.00 False │ │ Major_l4_WNT5B+ 0.00 False │ │ Myofibroblasts 0.00 False │ │ Inflammatory Fibroblasts 0.00 False │ │ Pericytes 0.00 False │ │ Microvascular 0.00 False │ │ Endothelial 0.00 False │ │ Post-capillary Venules 0.00 False │ │ Major_l4_TA cells 0.19 True │ │ Major_l4_Immature cells 0.00 False │ │ Major_l4_Absorptive Mature cells 0.00 False │ │ Major_l4_Progenitor cells 0.00 False │ │ Major_l4_Secretory Mature cells 0.00 False │ │ Plasma -0.22 True │ │ Cycling B 0.00 False │ │ Follicular 0.00 False │ │ GC 0.00 False │ │ Major_l4_CD8+ T 0.00 False │ │ Major_l4_CD4+ T 0.00 False │ │ Major_l4_DCs 0.00 False │ │ Macrophages 0.00 False │ │ Cycling Monocytes 0.00 False │ │ Inflammatory Monocytes 0.00 False │ │ CD69+ Mast 0.00 False │ │ CD69- Mast 0.00 False │ │ WNT2B+ Fos-lo 1 0.00 False │ │ WNT2B+ Fos-hi 0.00 False │ │ WNT2B+ Fos-lo 2 0.00 False │ │ RSPO3+ 0.00 False │ │ WNT5B+ 2 0.00 False │ │ WNT5B+ 1 0.00 False │ │ TA 1 0.00 False │ │ TA 2 0.00 False │ │ Enterocyte Progenitors 0.00 False │ │ Immature Enterocytes 2 0.00 False │ │ Immature Enterocytes 1 0.00 False │ │ Best4+ Enterocytes 0.00 False │ │ Enterocytes 0.00 False │ │ Immature Goblet 0.00 False │ │ Secretory TA 0.00 False │ │ Goblet 0.00 False │ │ Enteroendocrine 0.00 False │ │ Tuft 0.00 False │ │ CD8+ IELs 0.00 False │ │ Cycling T 0.00 False │ │ CD8+ IL17+ 0.00 False │ │ CD8+ LP 0.00 False │ │ Tregs 0.00 False │ │ CD4+ Activated Fos-hi 0.00 False │ │ CD4+ Activated Fos-lo -0.12 True │ │ CD4+ PD1+ 0.00 False │ │ CD4+ Memory 0.00 False │ │ MT-hi 0.00 False │ │ DC2 0.00 False │ │ DC1 0.00 False │ └─────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Model properties
First, the summary shows an overview over the model properties:
Number of samples/cell types
The reference cell type.
The formula used
The model has three types of parameters that are relevant for analysis - intercepts, feature-level effects and node-wise effects. These can be interpreted like in a standard regression model: Intercepts show how the cell types are distributed without any active covariates, effects show how the covariates influence the cell types.
Intercepts
The first column of the intercept summary shows the parameters determined by the MCMC inference.
The “Expected sample” column gives some context to the numerical values. If we had a new sample (with no active covariates) with a total number of cells equal to the mean sampling depth of the dataset, then this distribution over the cell types would be most likely.
Feature-level Effects
For the feature-level effect summary, the first column again shows the inferred parameters for all combinations of covariates and cell types, as sums over node-level effects on all parent nodes. Most important is the distinction between zero and non-zero entries A value of zero means that no statistically credible effect was detected. For a value other than zero, a credible change was detected. A positive sign indicates an increase, a negative sign a decrease in abundance.
Since the numerical values of the “Effect” column are not straightforward to interpret, the “Expected sample” and “log2-fold change” columns give us an idea on the magnitude of the change. The expected sample is calculated for each covariate separately (covariate value = 1, all other covariates = 0), with the same method as for the intercepts. The log-fold change is then calculated between this expected sample and the expected sample with no active covariates from the intercept section. Since the data is compositional, cell types for which no credible change was detected, will still change in abundance as well, as soon as a credible effect is detected on another cell type due to the sum-to-one constraint. If there are no credible effects for a covariate, its expected sample will be identical to the intercept sample, therefore the log2-fold change is 0.
Node-level effects
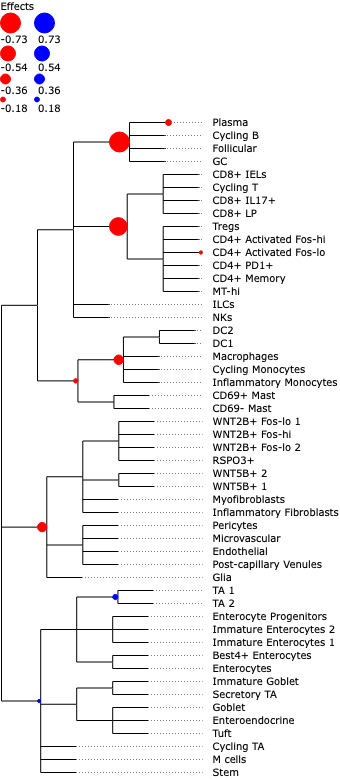
These parameters are the most important ones. They describe, at which points in the tree a credible change in abundance was detected. The data frame just has two columns: The “Final Parameter” column shows the effect values, the “Is credible” column simply depicts whether the inferred effect is different from 0, i.e. credible. In a normal tascCODA analysis, we are interested in which subtrees (i.e. nodes) have a nonzero effect, which we can easily extract:
tasccoda_model.credible_effects(smillie_data, modality_key="coda_LP")
Covariate Node
Health[T.Non-inflamed]_node Major_l1_Immune False
Major_l2_Stromal True
Major_l2_Epithelial True
Major_l2_Lymphoid False
Major_l2_Myeloid True
...
CD4+ PD1+ False
CD4+ Memory False
MT-hi False
DC2 False
DC1 False
Name: Final Parameter, Length: 74, dtype: bool
Interpretation
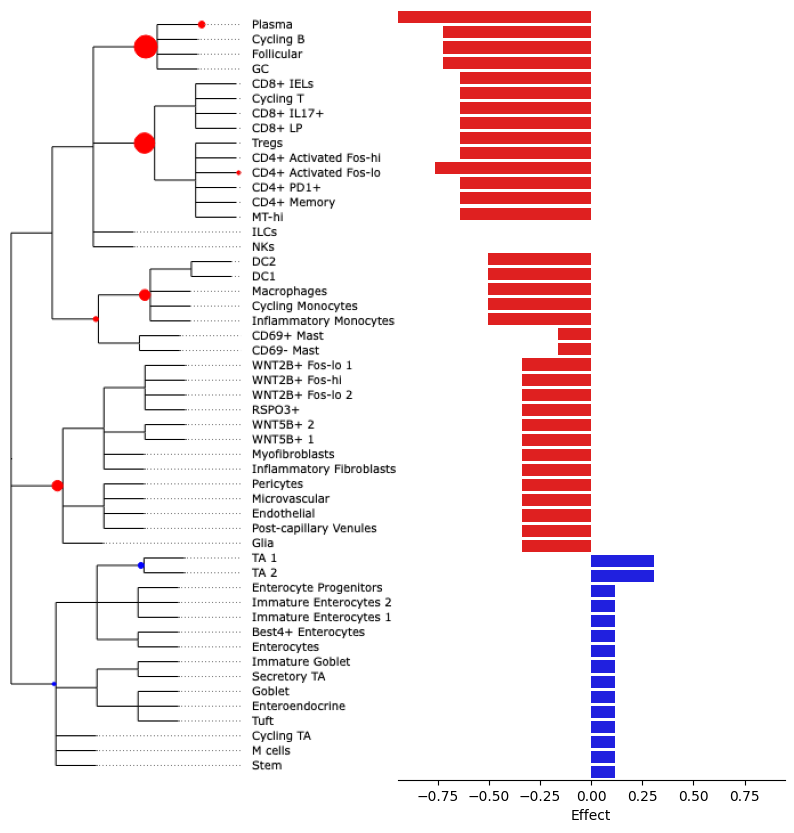
We see that most credible effects are on intermediate nodes. The only slight increase in abundance is on TA cells, while there are decreases on Stromal and some Immune cell types. The most important decreases (i.e. with the largest effect sizes) can be found on B- and T-cells. Plasma cells have an additional decrease, meaning that they change even stronger in abundance than the rest of the B-cell lineage.
We can also easily plot the credible effects as nodes on the tree for better visualization.
tasccoda_model.plot_draw_effects(
smillie_data,
modality_key="coda_LP",
tree=smillie_data["coda_LP"].uns["tree"],
covariate="Health[T.Non-inflamed]",
)
To better see the size of aggregated effects on the individual cell types, we can plot them at the side of the tree plot:
tasccoda_model.plot_draw_effects(
smillie_data,
modality_key="coda_LP",
tree=smillie_data["coda_LP"].uns["tree"],
covariate="Health[T.Non-inflamed]",
show_legend=False,
show_leaf_effects=True,
)
Wrote file: /Users/luisheinzlmeier/Desktop/Repos/pertpy/docs/tutorials/notebooks/tree_effect.png
/Users/luisheinzlmeier/Desktop/Repos/pertpy/pertpy/tools/_coda/_base_coda.py:2172: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `y` variable to `hue` and set `legend=False` for the same effect.
sns.barplot(data=leaf_effs, x="Effect", y="Cell Type", palette=palette, ax=ax[1])