pertpy.tools.Scgen#
- class Scgen(adata, n_hidden=800, n_latent=100, n_layers=2, dropout_rate=0.2, **model_kwargs)[source]#
Jax Implementation of scGen model for batch removal and perturbation prediction.
Attributes table#
Data attached to model instance. |
|
Manager instance associated with self.adata. |
|
The current device that the module's params are on. |
|
What the get normalized functions name is |
|
Returns computed metrics during training. |
|
Whether the model has been trained. |
|
Data attached to model instance. |
|
Returns the run id of the model. |
|
Returns the run name of the model. |
|
Summary string of the model. |
|
Observations that are in test set. |
|
Observations that are in train set. |
|
Observations that are in validation set. |
Methods table#
|
Removes batch effects. |
|
Converts a legacy saved model (<v0.15.0) to the updated save format. |
|
Returns the object in AnnData associated with the key in the data registry. |
|
Deregisters the |
|
|
|
Retrieves the |
|
Get decoded expression. |
|
Returns the object in AnnData associated with the key in the data registry. |
|
Return the latent representation for each cell. |
|
|
|
Returns the string provided to setup of a specific setup_arg. |
|
Returns the state registry for the AnnDataField registered with this instance. |
|
Variable names of input data. |
|
Instantiate a model from the saved output. |
|
Return the full registry saved with the model. |
|
Plots the dot product between delta and latent representation of a linear classifier. |
|
Plots mean matching for a set of specified genes. |
|
Plots variance matching for a set of specified genes. |
|
Predicts the cell type provided by the user in stimulated condition. |
|
Registers an |
|
Save the state of the model. |
|
Sets up the |
|
Move the model to the device. |
|
Train the model. |
|
Transfer fields from a model to an AnnData object. |
|
Update setup method args. |
|
Print summary of the setup for the initial AnnData or a given AnnData object. |
|
Prints summary of the registry. |
|
Print args used to setup a saved model. |
Prints setup kwargs used to produce a given registry. |
Attributes#
- Scgen.adata#
Data attached to model instance.
- Scgen.adata_manager#
Manager instance associated with self.adata.
- Scgen.device#
- Scgen.get_normalized_function_name#
What the get normalized functions name is
- Scgen.history#
Returns computed metrics during training.
- Scgen.is_trained#
Whether the model has been trained.
- Scgen.registry#
Data attached to model instance.
- Scgen.run_id#
Returns the run id of the model. Used in MLFlow
- Scgen.run_name#
Returns the run name of the model. Used in MLFlow
- Scgen.summary_string#
Summary string of the model.
- Scgen.test_indices#
Observations that are in test set.
- Scgen.train_indices#
Observations that are in train set.
- Scgen.validation_indices#
Observations that are in validation set.
Methods#
- Scgen.batch_removal(adata=None)[source]#
Removes batch effects.
- Parameters:
adata (
AnnData|None, default:None) – AnnData object with equivalent structure to initial AnnData. If None, defaults to the AnnData object used to initialize the model. Must have been setup with batch_key and labels_key, corresponding to batch and cell type metadata, respectively.- Return type:
- Returns:
A corrected ~anndata.AnnData object. AnnData of corrected gene expression in adata.X and corrected latent space in adata.obsm[“latent”]. A reference to the original AnnData is in corrected.raw if the input adata had no raw attribute.
Examples
>>> import pertpy as pt >>> data = pt.dt.kang_2018() >>> pt.tl.Scgen.setup_anndata(data, batch_key="label", labels_key="cell_type") >>> model = pt.tl.Scgen(data) >>> model.train(max_epochs=10, batch_size=64, early_stopping=True, early_stopping_patience=5) >>> corrected_adata = model.batch_removal()
- classmethod Scgen.convert_legacy_save(dir_path, output_dir_path, overwrite=False, prefix=None, **save_kwargs)#
Converts a legacy saved model (<v0.15.0) to the updated save format.
- Parameters:
dir_path (
str) – Path to the directory where the legacy model is saved.output_dir_path (
str) – Path to save converted save files.overwrite (
bool, default:False) – Overwrite existing data or not. IfFalseand directory already exists atoutput_dir_path, an error will be raised.prefix (
str|None, default:None) – Prefix of saved file names.**save_kwargs – Keyword arguments passed into
save().
- Return type:
- Scgen.data_registry(registry_key)#
Returns the object in AnnData associated with the key in the data registry.
- Scgen.deregister_manager(adata=None)#
Deregisters the
AnnDataManagerinstance associated with adata.If adata is None, deregisters all
AnnDataManagerinstances in both the class and instance-specific manager stores, except for the one associated with this model instance.
- Scgen.differential_abundance(*args, **kwargs)#
- Scgen.get_anndata_manager(adata, required=False)#
Retrieves the
AnnDataManagerfor a given AnnData object.Requires
self.idhas been set. Checks for anAnnDataManagerspecific to this model instance.- Parameters:
- Return type:
- Scgen.get_decoded_expression(adata=None, indices=None, batch_size=None)[source]#
Get decoded expression.
- Parameters:
adata (
AnnData|None, default:None) – AnnData object with equivalent structure to initial AnnData. If None, defaults to the AnnData object used to initialize the model.indices (
Sequence[int] |None, default:None) – Indices of cells in adata to use. If None, all cells are used.batch_size (
int|None, default:None) – Minibatch size for data loading into model. Defaults to scvi.settings.batch_size.
- Return type:
- Returns:
Decoded expression for each cell
Examples
>>> import pertpy as pt >>> data = pt.dt.kang_2018() >>> pt.tl.Scgen.setup_anndata(data, batch_key="label", labels_key="cell_type") >>> model = pt.tl.Scgen(data) >>> model.train(max_epochs=10, batch_size=64, early_stopping=True, early_stopping_patience=5) >>> decoded_X = model.get_decoded_expression()
- Scgen.get_from_registry(adata, registry_key)#
Returns the object in AnnData associated with the key in the data registry.
AnnData object should be registered with the model prior to calling this function via the
self._validate_anndatamethod.
- Scgen.get_latent_representation(adata=None, indices=None, give_mean=True, n_samples=1, batch_size=None)[source]#
Return the latent representation for each cell.
- Parameters:
adata (
AnnData|None, default:None) – AnnData object with equivalent structure to initial AnnData. If None, defaults to the AnnData object used to initialize the model.indices (
Sequence[int] |None, default:None) – Indices of cells in adata to use. If None, all cells are used.batch_size (
int|None, default:None) – Minibatch size for data loading into model. Defaults to scvi.settings.batch_size.give_mean (
bool, default:True) – Whether to return the meann_samples (
int, default:1) – The number of samples to use.
- Return type:
- Returns:
Low-dimensional representation for each cell
Examples
>>> import pertpy as pt >>> data = pt.dt.kang_2018() >>> pt.tl.Scgen.setup_anndata(data, batch_key="label", labels_key="cell_type") >>> model = pt.tl.Scgen(data) >>> model.train(max_epochs=10, batch_size=64, early_stopping=True, early_stopping_patience=5) >>> latent_X = model.get_latent_representation()
- Scgen.get_normalized_expression(*args, **kwargs)#
- Scgen.get_setup_arg(setup_arg)#
Returns the string provided to setup of a specific setup_arg.
- Return type:
- Scgen.get_state_registry(registry_key)#
Returns the state registry for the AnnDataField registered with this instance.
- Return type:
- classmethod Scgen.load(dir_path, adata=None, accelerator='auto', device='auto', prefix=None, backup_url=None, datamodule=None, allowed_classes_names_list=None)#
Instantiate a model from the saved output.
- Parameters:
dir_path (
str) – Path to saved outputs.adata (
AnnData|MuData|None, default:None) – AnnData organized in the same way as data used to train model. It is not necessary to run setup_anndata, as AnnData is validated against the saved scvi setup dictionary. If None, will check for and load anndata saved with the model. If False, will load the model without AnnData.accelerator (
str, default:'auto') – Supports passing different accelerator types (“cpu”, “gpu”, “tpu”, “ipu”, “hpu”, “mps, “auto”) as well as custom accelerator instances.device (
int|str, default:'auto') – The device to use. Can be set to a non-negative index (int or str) or “auto” for automatic selection based on the chosen accelerator. If set to “auto” and accelerator is not determined to be “cpu”, then device will be set to the first available device.prefix (
str|None, default:None) – Prefix of saved file names.backup_url (
str|None, default:None) – URL to retrieve saved outputs from if not present on disk.datamodule (
LightningDataModule|None, default:None) –EXPERIMENTALALightningDataModuleinstance to use for training in place of the defaultDataSplitter. Can only be passed in if the model was not initialized withAnnData.allowed_classes_names_list (
list[str] |None, default:None) – list of allowed classes names to be loaded (besides the original class name)
- Returns:
Model with loaded state dictionaries.
Examples
>>> model = ModelClass.load(save_path, adata) >>> model.get_....
- static Scgen.load_registry(dir_path, prefix=None)#
Return the full registry saved with the model.
- Scgen.plot_binary_classifier(scgen, adata, delta, ctrl_key, stim_key, *, fontsize=14, return_fig=False)[source]#
Plots the dot product between delta and latent representation of a linear classifier.
Builds a linear classifier based on the dot product between the difference vector and the latent representation of each cell and plots the dot product results between delta and latent representation.
- Parameters:
scgen (
Scgen) – ScGen object that was trained.adata (
AnnData|None) – AnnData object with equivalent structure to initial AnnData. If None, defaults to the AnnData object used to initialize the model. Must have been set up with batch_key and labels_key, corresponding to batch and cell type metadata, respectively.delta (
ndarray) – Difference between stimulated and control cells in latent spacectrl_key (
str) – Key for control part of the data found in condition_key.stim_key (
str) – Key for stimulated part of the data found in condition_key.fontsize (
float, default:14) – Set the font size of the plot.return_fig (
bool, default:False) – if True, returns figure of the plot, that can be used for saving.
- Return type:
- Returns:
If return_fig is True, returns the figure, otherwise None.
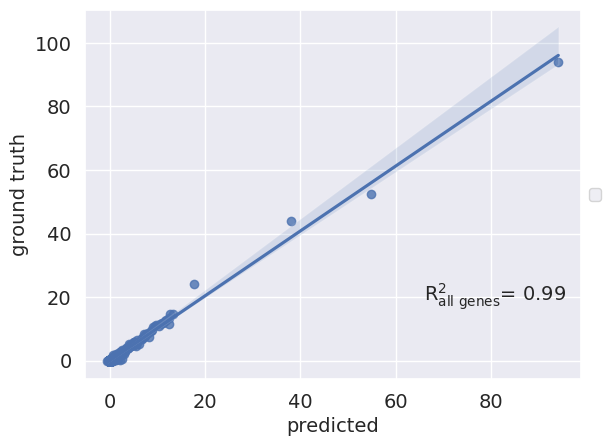
- Scgen.plot_reg_mean_plot(adata, condition_key, axis_keys, labels, *, gene_list=None, top_100_genes=None, verbose=False, legend=True, title=None, x_coeff=0.3, y_coeff=0.8, fontsize=14, show=False, save=None, **kwargs)[source]#
Plots mean matching for a set of specified genes.
- Parameters:
adata – AnnData object with equivalent structure to initial AnnData. If None, defaults to the AnnData object used to initialize the model. Must have been setup with batch_key and labels_key, corresponding to batch and cell type metadata, respectively.
condition_key (
str) – The key for the conditionaxis_keys (
dict[str,str]) – Dictionary of adata.obs keys that are used by the axes of the plot. Has to be in the following form: {x: Key for x-axis, y: Key for y-axis}.labels (
dict[str,str]) – Dictionary of axes labels of the form {x: x-axis-name, y: y-axis name}.gene_list (
list[str] |None, default:None) – list of gene names to be plotted.top_100_genes (
list[str] |None, default:None) – List of the top 100 differentially expressed genes. Specify if you want the top 100 DEGs to be assessed extra.verbose (
bool, default:False) – Specify if you want information to be printed while creating the plot.legend (
bool, default:True) – Whether to plot a legend.title (
str, default:None) – Set if you want the plot to display a title.x_coeff (
float, default:0.3) – Offset to print the R^2 value in x-direction.y_coeff (
float, default:0.8) – Offset to print the R^2 value in y-direction.fontsize (
float, default:14) – Fontsize used for text in the plot.show (
bool, default:False) – if True, will show to the plot after saving it.save (
str|bool|None, default:None) – Specify if the plot should be saved or not.**kwargs
- Return type:
- Returns:
Returns R^2 value for all genes and R^2 value for top 100 DEGs if top_100_genes is not None.
Examples
>>> import pertpy as pt >>> data = pt.dt.kang_2018() >>> pt.tl.Scgen.setup_anndata(data, batch_key="label", labels_key="cell_type") >>> scg = pt.tl.Scgen(data) >>> scg.train(max_epochs=10, batch_size=64, early_stopping=True, early_stopping_patience=5) >>> pred, delta = scg.predict(ctrl_key='ctrl', stim_key='stim', celltype_to_predict='CD4 T cells') >>> pred.obs['label'] = 'pred' >>> eval_adata = data[data.obs['cell_type'] == 'CD4 T cells'].copy().concatenate(pred) >>> r2_value = scg.plot_reg_mean_plot(eval_adata, condition_key='label', axis_keys={"x": "pred", "y": "stim"}, labels={"x": "predicted", "y": "ground truth"}, save=False, show=True)
- Preview:
- Scgen.plot_reg_var_plot(adata, condition_key, axis_keys, labels, *, gene_list=None, top_100_genes=None, legend=True, title=None, verbose=False, x_coeff=0.3, y_coeff=0.8, fontsize=14, show=True, save=None, **kwargs)[source]#
Plots variance matching for a set of specified genes.
- Parameters:
adata – AnnData object with equivalent structure to initial AnnData. If None, defaults to the AnnData object used to initialize the model. Must have been setup with batch_key and labels_key, corresponding to batch and cell type metadata, respectively.
condition_key (
str) – Key of the condition.axis_keys (
dict[str,str]) – Dictionary of adata.obs keys that are used by the axes of the plot. Has to be in the following form: {“x”: “Key for x-axis”, “y”: “Key for y-axis”}.labels (
dict[str,str]) – Dictionary of axes labels of the form {“x”: “x-axis-name”, “y”: “y-axis name”}.gene_list (
list[str], default:None) – list of gene names to be plotted.top_100_genes (
list[str], default:None) – List of the top 100 differentially expressed genes. Specify if you want the top 100 DEGs to be assessed extra.legend (
bool, default:True) – Whether to plot a legend.title (
str, default:None) – Set if you want the plot to display a title.verbose (
bool, default:False) – Specify if you want information to be printed while creating the plot.x_coeff (
float, default:0.3) – Offset to print the R^2 value in x-direction.y_coeff (
float, default:0.8) – Offset to print the R^2 value in y-direction.fontsize (
float, default:14) – Fontsize used for text in the plot.show (
bool, default:True) – if True, will show to the plot after saving it.save (
str|bool|None, default:None) – Specify if the plot should be saved or not.
- Return type:
- Scgen.predict(ctrl_key=None, stim_key=None, adata_to_predict=None, celltype_to_predict=None, restrict_arithmetic_to='all')[source]#
Predicts the cell type provided by the user in stimulated condition.
- Parameters:
ctrl_key (default:
None) – Key for control part of the data found in condition_key.stim_key (default:
None) – Key for stimulated part of the data found in condition_key.adata_to_predict (default:
None) – Adata for unperturbed cells you want to be predicted.celltype_to_predict (default:
None) – The cell type you want to be predicted.restrict_arithmetic_to (default:
'all') – Dictionary of celltypes you want to be observed for prediction.
- Return type:
- Returns:
numpy.ndarrayof predicted cells in primary space.
- delta: float
Difference between stimulated and control cells in latent space
Examples
>>> import pertpy as pt >>> data = pt.dt.kang_2018() >>> pt.tl.Scgen.setup_anndata(data, batch_key="label", labels_key="cell_type") >>> model = pt.tl.Scgen(data) >>> model.train(max_epochs=10, batch_size=64, early_stopping=True, early_stopping_patience=5) >>> pred, delta = model.predict(ctrl_key="ctrl", stim_key="stim", celltype_to_predict="CD4 T cells")
- classmethod Scgen.register_manager(adata_manager)#
Registers an
AnnDataManagerinstance with this model class.Stores the
AnnDataManagerreference in a class-specific manager store. Intended for use in thesetup_anndata()class method followed up by retrieval of theAnnDataManagervia the_get_most_recent_anndata_manager()method in the model init method.Notes
Subsequent calls to this method with an
AnnDataManagerinstance referring to the same underlying AnnData object will overwrite the reference to previousAnnDataManager.
- Scgen.save(dir_path, prefix=None, overwrite=False, save_anndata=False, save_kwargs=None, legacy_mudata_format=False, datamodule=None, **anndata_write_kwargs)#
Save the state of the model.
Neither the trainer optimizer state nor the trainer history are saved. Model files are not expected to be reproducibly saved and loaded across versions until we reach version 1.0.
- Parameters:
dir_path (
str) – Path to a directory.prefix (
str|None, default:None) – Prefix to prepend to saved file names.overwrite (
bool, default:False) – Overwrite existing data or not. If False and directory already exists at dir_path, an error will be raised.save_anndata (
bool, default:False) – If True, also saves the anndatasave_kwargs (
dict|None, default:None) – Keyword arguments passed intosave().legacy_mudata_format (
bool, default:False) – IfTrue, saves the modelvar_namesin the legacy format if the model was trained with aMuDataobject. The legacy format is a flat array with variable names across all modalities concatenated, while the new format is a dictionary with keys corresponding to the modality names and values corresponding to the variable names for each modality.datamodule (
LightningDataModule|None, default:None) –EXPERIMENTALALightningDataModuleinstance to use for training in place of the defaultDataSplitter. Can only be passed in if the model was not initialized withAnnData.anndata_write_kwargs – Kwargs for
write()
- classmethod Scgen.setup_anndata(adata, batch_key=None, labels_key=None, **kwargs)[source]#
Sets up the
AnnDataobject for this model.A mapping will be created between data fields used by this model to their respective locations in adata. None of the data in adata are modified. Only adds fields to adata.
scGen expects the expression data to come from adata.X
- batch_key
key in adata.obs for batch information. Categories will automatically be converted into integer categories and saved to adata.obs[‘_scvi_batch’]. If None, assigns the same batch to all the data.
- labels_key
key in adata.obs for label information. Categories will automatically be converted into integer categories and saved to adata.obs[‘_scvi_labels’]. If None, assigns the same label to all the data.
Examples
>>> import pertpy as pt >>> data = pt.dt.kang_2018() >>> pt.tl.Scgen.setup_anndata(data, batch_key="label", labels_key="cell_type")
- Scgen.to_device(device)[source]#
Move the model to the device.
- Parameters:
device – Device to move model to. Options: ‘cpu’ for CPU, integer GPU index (e.g., 0), ‘cuda:X’ where X is the GPU index (e.g. ‘cuda:0’), or a torch.device object (including XLA devices for TPU). See torch.device for more info.
Examples
>>> adata = scvi.data.synthetic_iid() >>> model = scvi.model.SCVI(adata) >>> model.to_device("cpu") # moves model to CPU >>> model.to_device("cuda:0") # moves model to GPU 0 >>> model.to_device(0) # also moves model to GPU 0
- Scgen.train(max_epochs=None, accelerator='auto', devices='auto', train_size=None, validation_size=None, shuffle_set_split=True, batch_size=128, datasplitter_kwargs=None, plan_config=None, plan_kwargs=None, trainer_config=None, **trainer_kwargs)#
Train the model.
- Parameters:
max_epochs (
int|None, default:None) – Number of passes through the dataset. If None, defaults to np.min([round((20000 / n_cells) * 400), 400])accelerator (
str, default:'auto') – Supports passing different accelerator types (“cpu”, “gpu”, “tpu”, “ipu”, “hpu”, “mps, “auto”) as well as custom accelerator instances.devices (
int|list[int] |str, default:'auto') – The devices to use. Can be set to a non-negative index (int or str), a sequence of device indices (list or comma-separated str), the value -1 to indicate all available devices, or “auto” for automatic selection based on the chosen accelerator. If set to “auto” and accelerator is not determined to be “cpu”, then devices will be set to the first available device.train_size (
float|None, default:None) – Size of training set in the range [0.0, 1.0].validation_size (
float|None, default:None) – Size of the test set. If None, defaults to 1 - train_size. If train_size + validation_size < 1, the remaining cells belong to a test set.shuffle_set_split (
bool, default:True) – Whether to shuffle indices before splitting. If False, the val, train, and test set are split in the sequential order of the data according to validation_size and train_size percentages.batch_size (
int, default:128) – Minibatch size to use during training.lr – Learning rate to use during training.
datasplitter_kwargs (
dict|None, default:None) – Additional keyword arguments passed intoDataSplitter.plan_kwargs (
Mapping[str,Any] |KwargsConfig|None, default:None) – Keyword args forJaxTrainingPlan. Keyword arguments passed to train() will overwrite values present in plan_kwargs, when appropriate.plan_config (
Mapping[str,Any] |KwargsConfig|None, default:None) – Configuration object or mapping used to buildJaxTrainingPlan. Values inplan_kwargsand explicit arguments take precedence.trainer_config (
Mapping[str,Any] |KwargsConfig|None, default:None) – Configuration object or mapping used to buildTrainer. Values intrainer_kwargsand explicit arguments take precedence.**trainer_kwargs – Other keyword args for
Trainer.
- Scgen.transfer_fields(adata, **kwargs)#
Transfer fields from a model to an AnnData object.
- Return type:
- Scgen.update_setup_method_args(setup_method_args)#
Update setup method args.
- Parameters:
setup_method_args (
dict) – This is a bit of a misnomer, this is a dict representing kwargs of the setup method that will be used to update the existing values in the registry of this instance.
- Scgen.view_anndata_setup(adata=None, hide_state_registries=False)#
Print summary of the setup for the initial AnnData or a given AnnData object.
- Scgen.view_registry(hide_state_registries=False)#
Prints summary of the registry.
- static Scgen.view_setup_args(dir_path, prefix=None)#
Print args used to setup a saved model.